Planning in general - not just in software development - is not an easy thing. We have to know what to do next and have an idea when it will be ready. Although the former is harder the latter seems to be more problematic. We also struggled with it with my old team at Digital Natives. We had frequent and long planning meetings, and had rarely finished everything we had planned. So, we decided it was enough, and it was time to try something new. After about two months, we were able to give very accurate hour based predictions on spent time and delivery (lead time) with a quarter of the effort of our previous planning meetings.
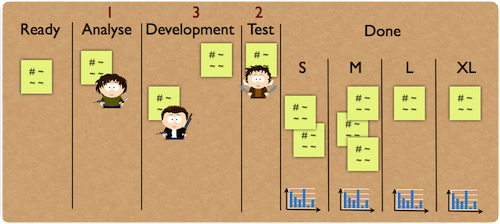
We started a new board - not a Kanban board - where we collected the already finished work items:

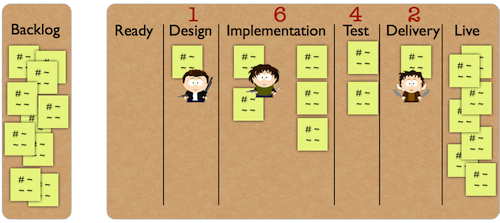
As you can see this board had three different columns. Each column represented a T-shirt size: ‘S’, ‘M’, and ‘L’. When we set up this board we put all the work items we had into these columns based on difficulty. Our smart questions were: “was this work item hard to do?” and “was it harder than these work items in this column?”. With this approach we ended up with three columns and since we weren’t able to find right titles for the them we named them T-shirt sizes. We calculated the lead time and spent time using distribution diagrams for each, and wrote them on the board (you can see them on the next picture). At the end of each week, we recalculated and put them on the board in order to use always the latest data for our predictions. When a work item was finished we put it into its proper column.

When we got a new work item, we gathered around the board, and we tried to estimate the right difficulty for the new work. Then we wrote ‘S’, ‘M’, or ‘L’ on the card and put it on our Kanban board. During the daily meeting our product owner checked the new work items on the board. When he thought that an item would take too long - its predicted spent time based on its size was too much - he asked us to cut the work item into pieces or he reduced the scope just to let something hit the market sooner. Our weekly inflow was around 7 work items, we spent around 5 minutes on finding the right place for the card, so our planning effort was a bit more than half an hour. Before that we have never finished our planning meeting in under two hours. The other big gain was that we could get rid of Scrum sprints and could work continuously: the planning meeting wasn’t an obstacle any more.
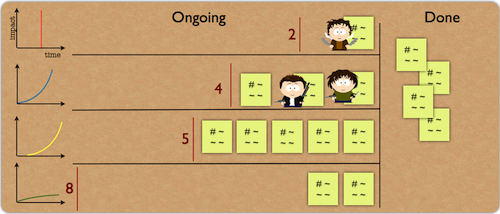
After several weeks, we observed that our predictions were not as good as before. There were ‘M’ sized items that were finished sooner, and vice versa. After a retrospective meeting we concluded that some of our data had expired. We were getting better at what we were doing, learned a lot about the product, and did several minor improvements in the meantime, therefore our old data was no longer useful. So we introduced lines on our board. Each line represented a week, and the latest was on the top (it took about 5 minutes to shift the whole board down each week, so it wasn’t a big effort). When we were doing the planning we considered only the last three weeks.
 Of course we were wrong several times. The note on the right shows a transformation from ‘S’ -> ‘M’. After a work item was finished we took it from our Kanban board and move it to the other board. When a work item took more time than we had originally predicted, we tried to find the right place for it. The work item above was predicted as ‘S’ but actually was an ‘M’, so we put it into the ‘M’ column. With this technique we kept our board up to date. Of course, if it was an ‘S’ but we predicted an ‘M’ we did the same routine. This ‘S’ -> ‘M’ marker became very helpful later. There is an inner voice that tells us “next time you’ll do better”, but this marker kept us from listening to it. If the new work item was similar to a card with ‘S’ -> ‘M’, we wouldn’t mark it as ‘S’ because we knew that we had problems with predicting similar work items before, so it became an ‘M’. Most of time we were right, and I’m still very happy about it, because we were making decisions based on data and not gut feeling. Moreover, we were also looking for certain keywords. For example, if a work item had the word ‘wizard’ in its description it couldn’t get into the ‘S’ column, ever. Even if it was a text change on the UI. We tried several times to finish a ‘wizard’ related work within ‘S’ scope, and we never succeeded. So, the minimum an ‘wizard’ work item could get was an ‘M’. And our product owner was okay with this (I guess he valued predictability and quality over speed).
Of course we were wrong several times. The note on the right shows a transformation from ‘S’ -> ‘M’. After a work item was finished we took it from our Kanban board and move it to the other board. When a work item took more time than we had originally predicted, we tried to find the right place for it. The work item above was predicted as ‘S’ but actually was an ‘M’, so we put it into the ‘M’ column. With this technique we kept our board up to date. Of course, if it was an ‘S’ but we predicted an ‘M’ we did the same routine. This ‘S’ -> ‘M’ marker became very helpful later. There is an inner voice that tells us “next time you’ll do better”, but this marker kept us from listening to it. If the new work item was similar to a card with ‘S’ -> ‘M’, we wouldn’t mark it as ‘S’ because we knew that we had problems with predicting similar work items before, so it became an ‘M’. Most of time we were right, and I’m still very happy about it, because we were making decisions based on data and not gut feeling. Moreover, we were also looking for certain keywords. For example, if a work item had the word ‘wizard’ in its description it couldn’t get into the ‘S’ column, ever. Even if it was a text change on the UI. We tried several times to finish a ‘wizard’ related work within ‘S’ scope, and we never succeeded. So, the minimum an ‘wizard’ work item could get was an ‘M’. And our product owner was okay with this (I guess he valued predictability and quality over speed).
You may wonder about a couple of things. First, why were we tracking both the lead and spent time? We were kind of working in a TTM (time to market) fashion so it mattered how much time we spent on this project during a week or a month, so the spent time was important. On the other hand we needed the lead time to predict when a work item could be delivered. We weren’t doing continuous delivery - we did continuous deployment - so it was good to know when we can deploy.
Second, what has happened to the architectural decision part of a planning meeting? During a typical Scrum planning meeting, the teams kind of make architectural decisions as well. We didn’t stop doing this. We changed our process so that we did this planning for each new work item when it could get into the ‘analyse’ phase (before implementation). So in general the time we spent on planning didn’t change much. What changed is the time we spent on a regular planning meeting, and we reduced some mura waste: we planned when it was necessary, and therefore we had fewer re-planning sessions than before.
And third, the environment. When we started to do this kind of planning we knew the domain, knew each other and our technical knowledge was kind of the same. The size of the team changed over time, but this affected only the lead time because we rarely worked on work items in pairs.
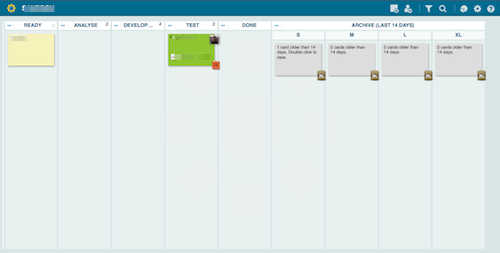
I really enjoyed working like this. It was stressless: no hassle around deadlines and estimations, because everything we did was predicable most of the time. Of course, when we had some performance issues we had some stress, but not because of planning and execution of plans. The pictures above were taken after four weeks of usage but we used this technique for three months until the end of the project. I can only recommend this technique, and if you are interested in the #noEstimates movement, this is a good start. You don’t need a physical board either. You can have a bit wider Done column, or a different kind of Archive board. Here is an example from Leankit:
Related posts you may find also interesting:
]]>
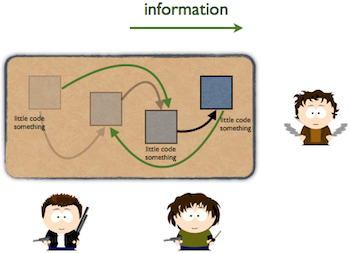



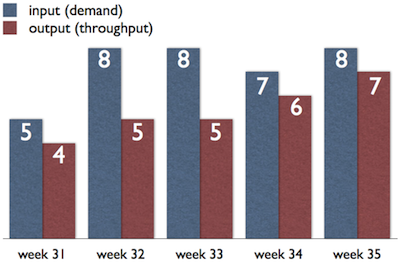
 CONWIP stands for constant work in progress which means that the overall number of work items in the system is limited, not just a single phase or column. For example, with a CONWIP of 6 we can have at most 6 work items between ‘todo’ and ‘done’. Like throughtput, takt time, and flow efficiency CONWIP comes from the car manufacturing world and it was designed for a system that produces the same kind of work item over and over. The idea is the following: it is hard to control throughtput (it is a lag measure: it provides a value that applies to a period in the past) while it is relative easy to control the overall number work items (real kanban cards and pulls) in the whole system. For example, our factory produces two kinds of product ‘A’ and ‘B’. At the moment the market needs more of ‘A’ and less of ‘B’, we simply reduce the CONWIP of ‘B’ and increase the CONWIP of ‘A’ (we do product leveling). This will change the throughput. When the demand changes we change the CONWIP values accordingly. Like the previously mentioned metrics, CONWIP cannot be used as such in software development, but after putting it into context it is very helpful.
CONWIP stands for constant work in progress which means that the overall number of work items in the system is limited, not just a single phase or column. For example, with a CONWIP of 6 we can have at most 6 work items between ‘todo’ and ‘done’. Like throughtput, takt time, and flow efficiency CONWIP comes from the car manufacturing world and it was designed for a system that produces the same kind of work item over and over. The idea is the following: it is hard to control throughtput (it is a lag measure: it provides a value that applies to a period in the past) while it is relative easy to control the overall number work items (real kanban cards and pulls) in the whole system. For example, our factory produces two kinds of product ‘A’ and ‘B’. At the moment the market needs more of ‘A’ and less of ‘B’, we simply reduce the CONWIP of ‘B’ and increase the CONWIP of ‘A’ (we do product leveling). This will change the throughput. When the demand changes we change the CONWIP values accordingly. Like the previously mentioned metrics, CONWIP cannot be used as such in software development, but after putting it into context it is very helpful.



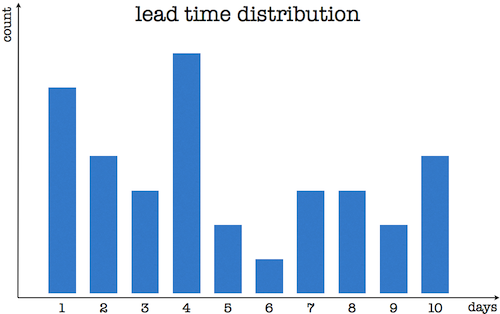


 Last year in the Lean Kanban University conference series I was talking about flow efficiency and how we measured and used it with one of my old teams. My friend Chris McDermott asked me to write a post about it, so here it comes. Like other metrics such as cycle time, takt time, and throughput, flow efficiency comes from car manufacturing. It shows the time in working time/lead time in progress percentage for a given work item (check out the equation on the right). So a 100% flow efficiency means that the work item is never idle during processing. If a work item was done in 60 minutes and its flow efficiency was 5% means that one worked only 3 minutes on that particular item. In a factory it must be fairly easy to calculate flow efficiency because the flow is semi- or completely automatic, and therefore the machines that move the work items around can log the pickup and delivery times and that makes it easy to calculate the working time itself. In software development such logging would increase the time spent on administrative tasks, and the current electronic Kanban tools don’t know when a work item is idle or is one is working on it. It is not a lost cause, because we know the overall time we spent on a work item, and we also know the lead time.
Last year in the Lean Kanban University conference series I was talking about flow efficiency and how we measured and used it with one of my old teams. My friend Chris McDermott asked me to write a post about it, so here it comes. Like other metrics such as cycle time, takt time, and throughput, flow efficiency comes from car manufacturing. It shows the time in working time/lead time in progress percentage for a given work item (check out the equation on the right). So a 100% flow efficiency means that the work item is never idle during processing. If a work item was done in 60 minutes and its flow efficiency was 5% means that one worked only 3 minutes on that particular item. In a factory it must be fairly easy to calculate flow efficiency because the flow is semi- or completely automatic, and therefore the machines that move the work items around can log the pickup and delivery times and that makes it easy to calculate the working time itself. In software development such logging would increase the time spent on administrative tasks, and the current electronic Kanban tools don’t know when a work item is idle or is one is working on it. It is not a lost cause, because we know the overall time we spent on a work item, and we also know the lead time.